Se aplica A: Fireboxes administrados en la nube, Fireboxes administrados localmente
En la página FireCluster, puede ver el estado en vivo de los FireClusters administrados en la nube y de los FireClusters administrados localmente con los informes en la nube habilitados. También puede consultar el historial de eventos y un informe detallado de cada evento.
Esta página solo está disponible cuando su FireCluster administrado en la nube o su FireCluster administrado localmente con informes en la nube, está conectado a WatchGuard Cloud. Ambos miembros del clúster deben ejecutar Fireware v12.8.2 o superior (o v12.5.11 o superior para los Fireboxes T30, T35, T50, M200 y M300).
Para monitorizar FireClusters en Fireboxes administrados en la nube y Fireboxes administrados localmente con informes en la nube:
- Seleccione Monitorizar > Dispositivos.
- Seleccione un Firebox.
Se abre la página Resumen de Dispositivo para el Firebox seleccionado. - Seleccione Estado en Vivo > FireCluster.
Se abre la página FireCluster.
Para abrir el estado en vivo en una nueva ventana, haga clic en  en la esquina superior derecha de la ventana de WatchGuard Cloud.
en la esquina superior derecha de la ventana de WatchGuard Cloud.
El gráfico Historial de Eventos muestra un historial de eventos codificado por colores para ambos miembros del clúster. El gráfico muestra los eventos de los últimos tres meses.
Blanco (Ambos Miembros Inactivos)
Las secciones blancas del gráfico indican los momentos en los que los dos miembros del clúster no estaban disponibles.
Naranja (Un Solo Miembro Activo)
Las secciones naranjas del gráfico indican los momentos en los que solo un miembro del clúster no estaba disponible.
Verde (Ambos Miembros Activos)
Las secciones verdes del gráfico indican los momentos en los que ambos miembros del clúster estaban disponibles.
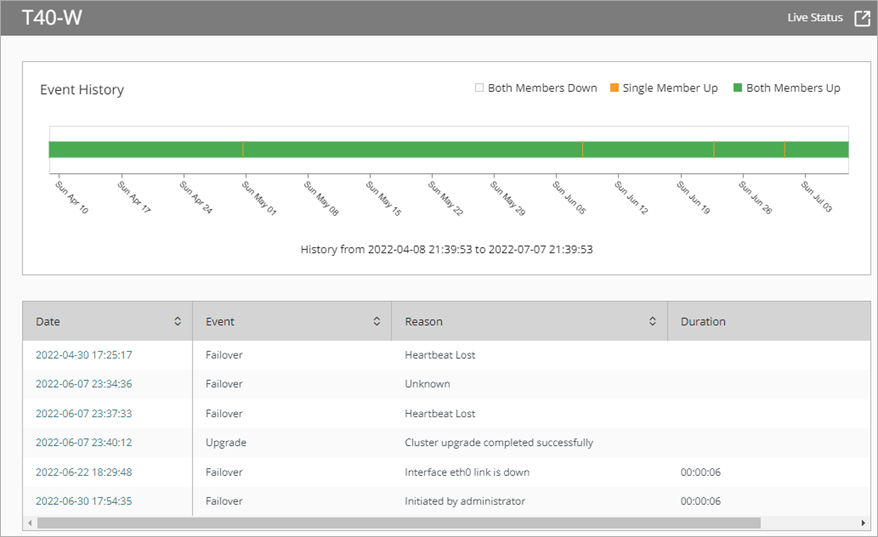
La tabla de eventos incluye los eventos del clúster ocurridos en los últimos tres meses. La tabla incluye estas columnas:
Fecha
La fecha y hora en que ocurrió el evento del clúster.
Evento
El tipo de evento que se produjo, como una conmutación por error o una actualización de firmware.
Motivo
La razón por la que se produjo el evento, como una pérdida de latido o una actualización de firmware iniciada por un administrador.
Duración
El tiempo transcurrido durante el evento.
Para ver un informe detallado de un evento, en la columna Fecha, haga clic en la fecha del evento. Se abre el informe del evento que incluye esta información:
Descripción del evento
El tipo de evento, el motivo del evento y la hora del evento.
Estado del tiempo de ejecución
Si los miembros del clúster están en línea y sincronizados entre sí, el porcentaje de uso de CPU y memoria, la cantidad de conexiones del Firebox y la tasa de conexión por segundo (CPS).
Estado de tiempo de ejecución del clúster
El ID del clúster, los miembros actuales del clúster principal y de respaldo, el estado de todas las interfaces del clúster y el umbral de latido.
El maestro del clúster envía un paquete de latido a través de las interfaces del clúster principal y de respaldo una vez por segundo. Si el maestro de respaldo no recibe tres latidos consecutivos del maestro del clúster, esto dispara una conmutación por error del clúster principal. El umbral predeterminado para los latidos perdidos es tres.
Estos estados no son admitidos: Canal de Transmisión de Archivos, Canal de Transmisión de Mensajes, Mensajes KeepAlive y Mensajes de Latido.
Información de Salud del Clúster
Puntuaciones para el Índice de Salud del Sistema (SHI), el Índice de Salud de los Puertos Monitorizados (MPHI) y el Índice Promedio Ponderado (WAI). Cada índice de salud puede tener un valor desde 0 hasta 100.
El SHI indica el estado de los procesos monitorizados en el dispositivo. Si todos los procesos monitorizados están activos, el valor SHI es 100.
El MPH indica el estado de los puertos monitorizados. Si todos los puertos monitorizados están funcionando, el valor SHI es 100. El estado de las conexiones inalámbricas no es monitorizado como parte de este índice.
El WAI se usa para comparar la salud general de dos miembros del clúster como un criterio para conmutación por error. El WAI de un miembro del clúster es un promedio ponderado del SHI y el MPHI de ese dispositivo. Si el WAI del maestro del clúster es menor que el WAI del maestro de respaldo, el maestro del clúster tiene una conmutación por error.
El Índice de Salud del Hardware (HHI) está deshabilitado para los FireCluster administrados en la nube.
Estado de las interfaces del clúster
Si una interfaz está activada o desactivada.
Sincronización de la VPN
La cantidad de túneles BOVPN activos.
Eventos de funcionamiento del clúster
Una lista cronológica de eventos relacionados con las operaciones del clúster, como la formación del clúster, las actualizaciones de firmware y los cambios de rol de los miembros del clúster.

Para descargar una versión .JSON del informe del evento, haga clic en ![]() .
.
Acerca de FireCluster en WatchGuard Cloud
Administrar la Generación de Registros del FireCluster en WatchGuard Cloud
Configurar los Ajustes del Log Server para los Fireboxes Administrados en la Nube